Using the XOR Graphical User Interface
The graphical user interface presented here has been built with the purpose to educate the analyst about the main workflows needed to run a privacy preserving distributed computation using XOR. This interface has been built using the underlying XOR APIs and can be used as a reference guide to integrate XOR's API into an existing web application.
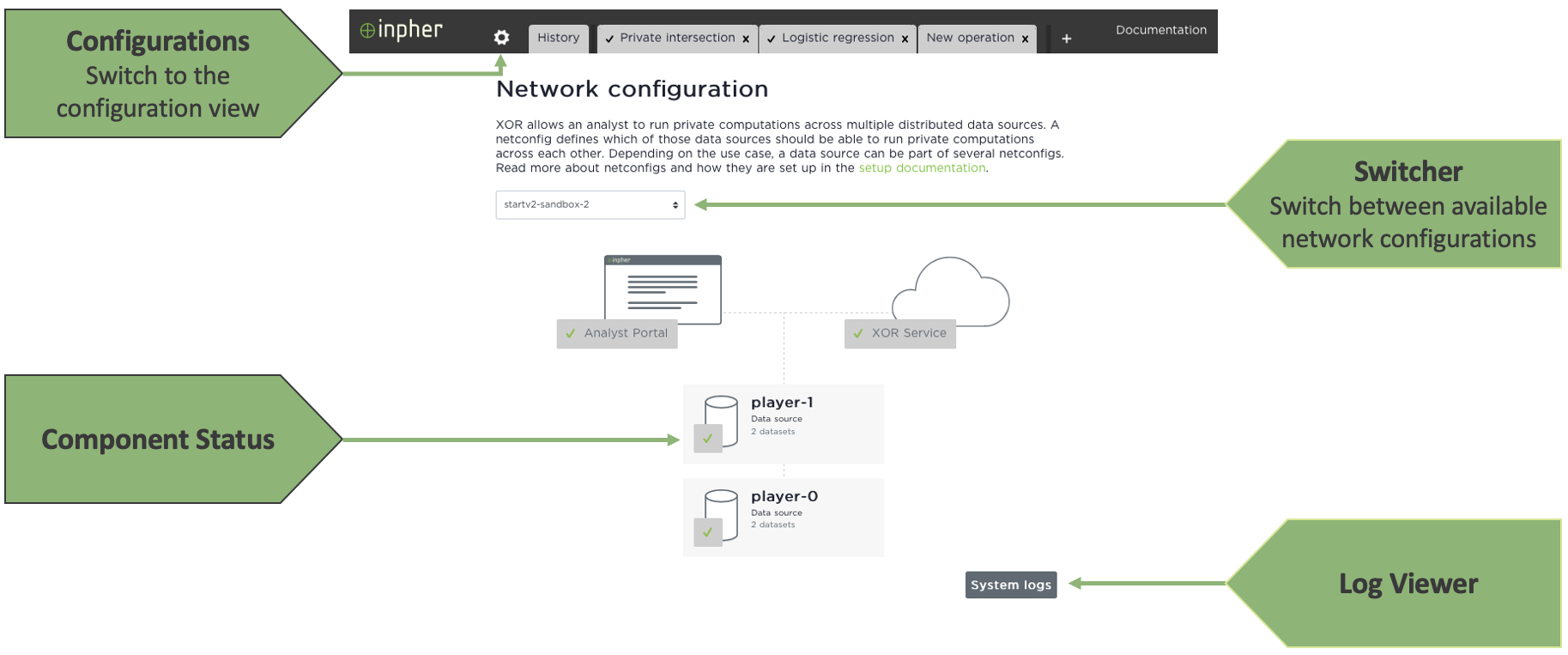
Selecting a netconfig
As an analyst, the first step is to choose the appropriate network configuration. A "netconfig" is a collection of distributed data sources located in distinct privacy zones served by XOR Machines.
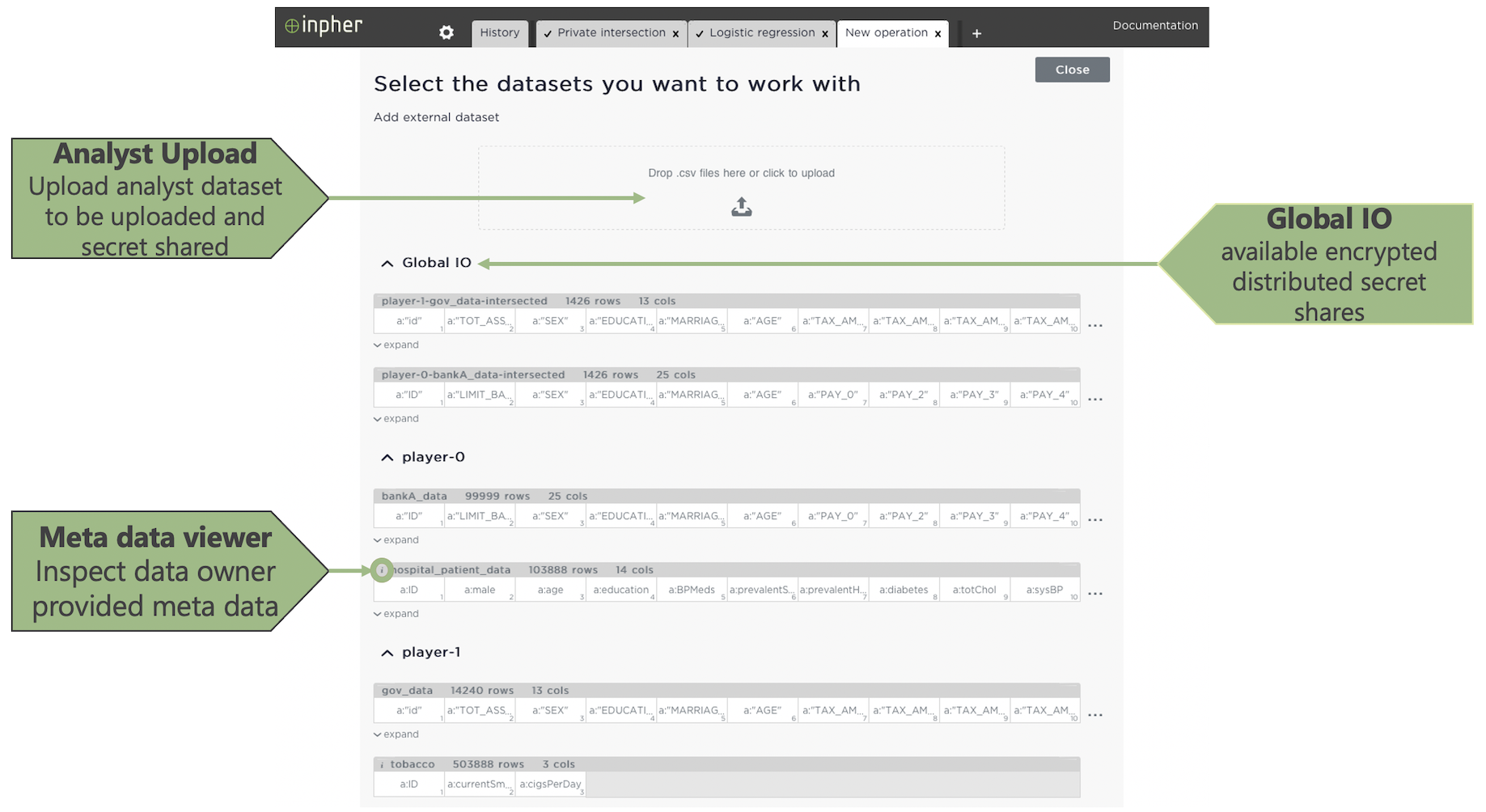
Selecting datasets
Once a netconfig has been selected, the analyst proceeds by exploring and selecting the available datasets. If the data owner connected their data catalogue, or provided additional meta data or schemas, they will be available to the XOR analyst. Datasets in "PDDStore" are encrypted distributed secret shares that can be used for computations but can't be seen by any party. These datasets are typically secret shares uploaded by the analyst or results from previous computations.
Dataset composition
Once the datasets have been selected, they can be composed by stacking them vertically, horizontally or a combination of both.
The analyst specifies the dataset(s) to use with their corresponding letter (e.g. A, B, C, ...).
# Grouping
Use ( ) to specify the columns to use. E.g. A(1-4,6,12-13)
Use [ ] to specify the rows to use. E.g. A[1-421,256-350]
# Stacking
Use : to append columns to the right of the previous dataset(s) equivalent to python hstack
Use ; to append rows below the previous dataset(s) equivalent to python vstack
You can combine different expressions provided the result is consistent.
E.g. A(1-4)[1-500]:B(2,5-6)[1-500]
E.g. B(2,5-6);C(1-3)[1-120]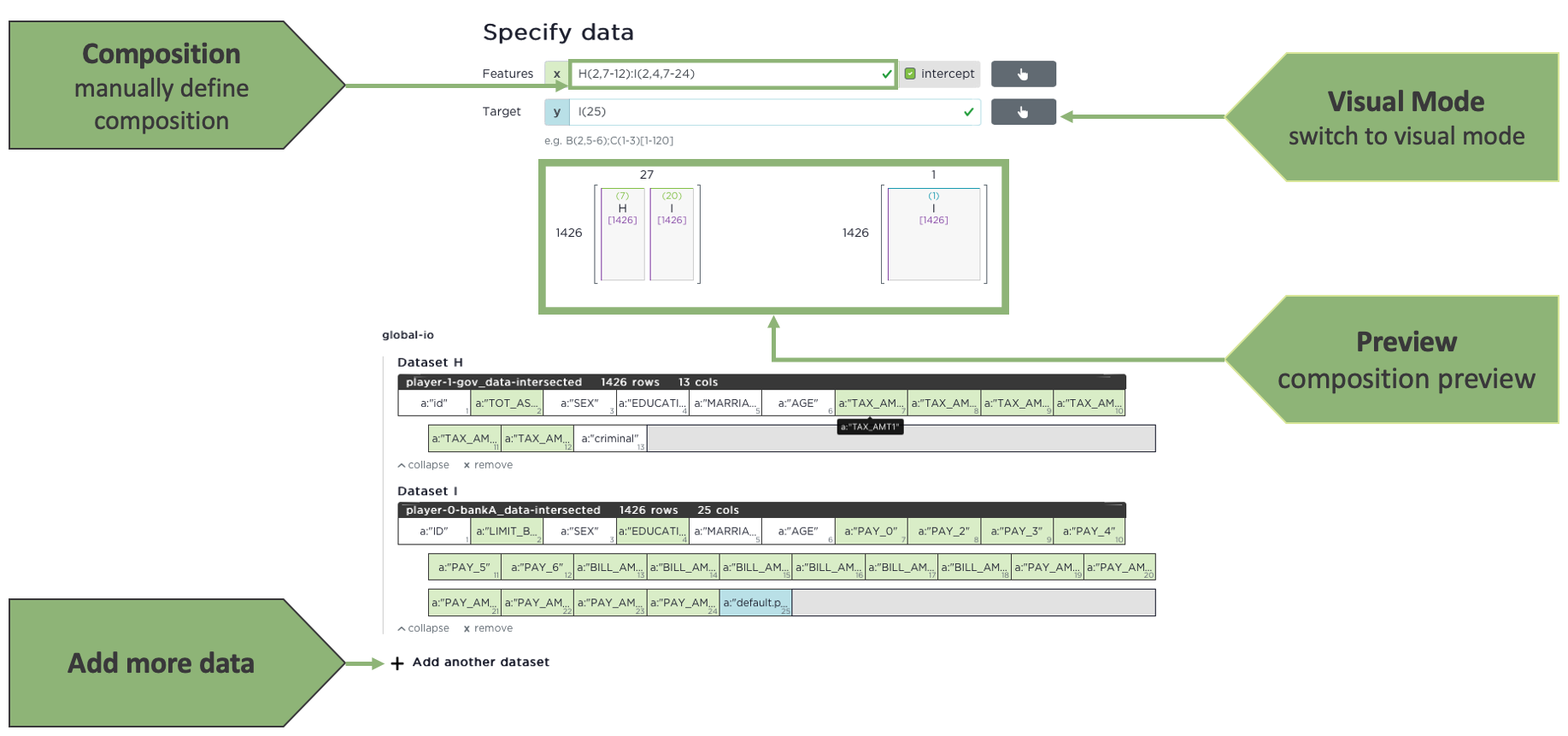
Selecting an operation
After composing the datasets, the analyst chooses the operation to be run on this on this dataset along with parameters. Refer to the algorithms section for more details on available algorithms.

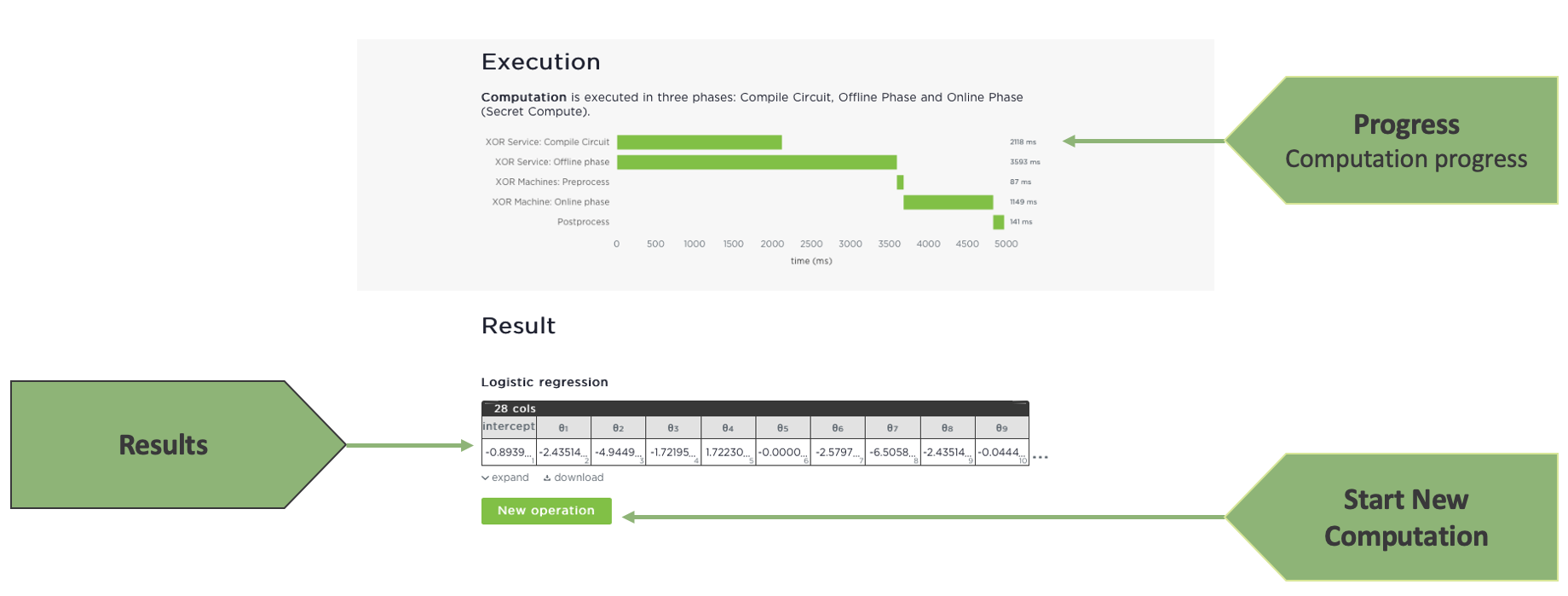
Running an operation
Once the operation is selected and the datasets have been composed. The computation can be triggered. The running time and status of an operation can be tracked in the UI and depend on the complexity of the operation and the size of the datasets. Once the computations completes, the results are either revealed to the analyst or exported as encrypted shares to the PDDStore.
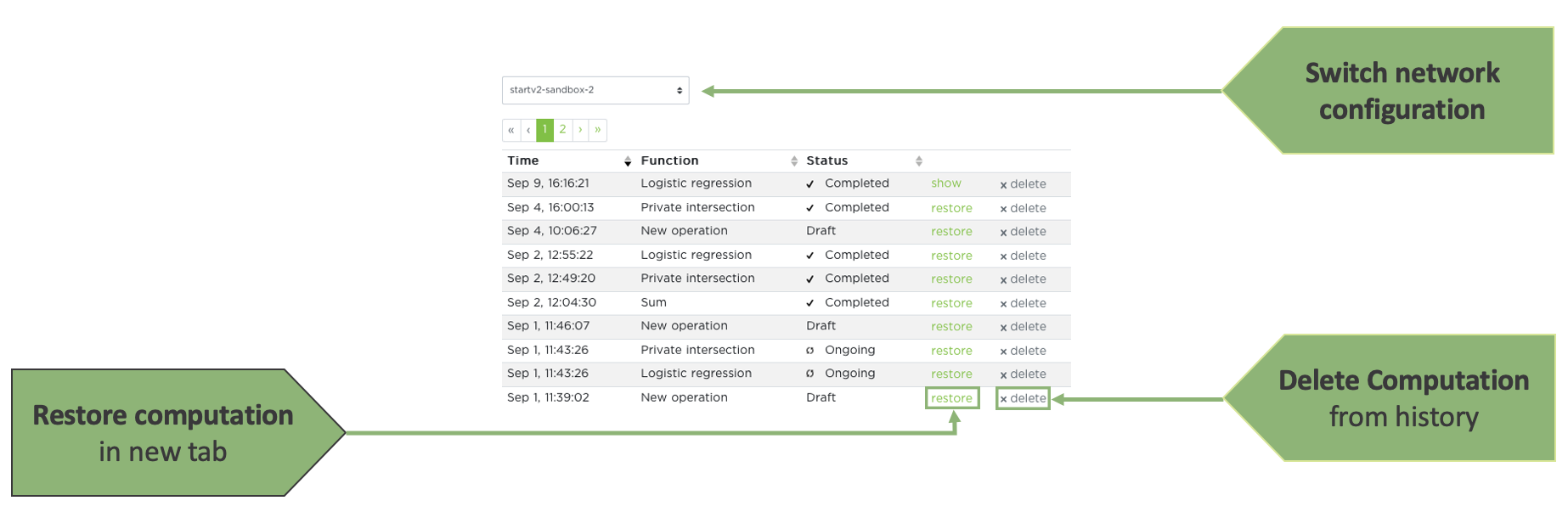
Operation History